Is Google’s AI research about to implode?
What does Timnit Gebru’s firing and the recent papers coming out of Google tell us about the state of research at the world’s biggest AI research department.
The high point for Google’s research in to Artifical Intelligence may well turn out to be the 19th of October 2017. This was the date that David Silver and his co-workers at DeepMind published a report, in the journal Nature, showing how their deep-learning algorithm AlphaGo Zero was a better Go player than not only the best human in the world, but all other Go-playing computers.
What was most remarkable about AlphaGo Zero was that it worked without human assistance. The researchers set up a neural network, let it play lots of games of Go against itself and a few days later it was the best Go player in the world. Then they showed it chess and it took only four hours to become the best chess player in the world. Unlike previous game-playing algorithms there was no rulebook built in to the algorithm or specialised search algorithm, just a machine playing game after game, from novice up to master level, all the way up to a level where nobody, computer or person, could beat it.
But there was a problem.
Maybe it wasn’t Silver and his colleagues’ problem, but it was a problem all the same. The DeepMind research program had shown what deep neural networks could do, but it had also revealed what they couldn’t do. For example, although they could train their system to win at Atari games Space Invaders and Breakout, it couldn’t play games like Montezuma Revenge where rewards could only be collected after completing a series of actions (for example, climb down ladder, get down rope, get down another ladder, jump over skull and climb up a third ladder). For these types of games, the algorithms can’t learn because they require an understanding of the concept of ladders, ropes and keys. Something us humans have built in to our cognitive model of the world. But also something that can’t be learnt by the reinforcement learning approach that DeepMind applied.

Another example of the limitations of the deep learning approach can be found in language models. One approach to getting machines to understand language, pursued at Google Brain as well as Open AI and other research institutes, is to train models to predict sequences of words and sentences in large corpuses of text. This approach goes all the way back to 1913 and the work of Andrej Markov, who used it to predict the order of vowels and consonants in Pushkin’s novel in verse Eugene Onegin. There are well defined patterns within language and by ‘learning’ those patterns an algorithm can speak that language.
The pattern detecting approach to langauge is interesting in the sense that it can reproduce paragraphs that seem to make sense, at least superficially. A nice example of this was published in The Guardian in September 2020, where an AI mused on whether computers could bring world peace. But, as Emily Bender, Timnit Gebru and co-workers point out in their recent paper ‘On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?’ these techniques do not understand what we are writing. They are simply storing language in a convenient form and the outputs they produce are just parroting the data. And, as the example below shows, these ouputs can be dangerously untrue. Primed with data about QAnon, the GPT-3 language model produces lies and conspiracy theories.

Bender and her colleagues explain that many of the corpuses of text available to researchers — from, for example, Reddit and entertainment news sites — contain incorrect information and are highly biased in the way they represent the world. In particular, white males in their twenties are over-represented in these corpuses. Furthermore, in making certain “corrections” to large datasets, for example removing references to sex, the voices of LGBTQ people will be given less prominence. The lack of transparency and accountability in the data makes these models useless for anything other than generating amusing Guardian articles (my words, not the authors). But they have substantial negative consequences: in producing reems of factually incorrect texts and requiring computing resources that can have a major environmental impact.
When Gebru sent the paper with Bender for internal review at Google it was rejected, although it was susequently accepted after rigorous external peer-review for publication. Gebru was later fired for objecting to her manager’s request to retract or remove her name from the paper.
Yet she is not alone in critising the way machine learning research is playing out at Google.
In an article that came out a few weeks before Gebru’s firing, 40 Google researchers, from throughout the organisation, raised serious issues around machine learning approaches to a wide-range of problems. They used an example of modelling an epidemic to illustrate their concerns. The image below shows two epidemic curves predicted by a machine learning model, but based on different assumptions about disease spread. Both models are equally good, accordning to the algorithm, but they make very different predictions about the eventual size of an epidemic.
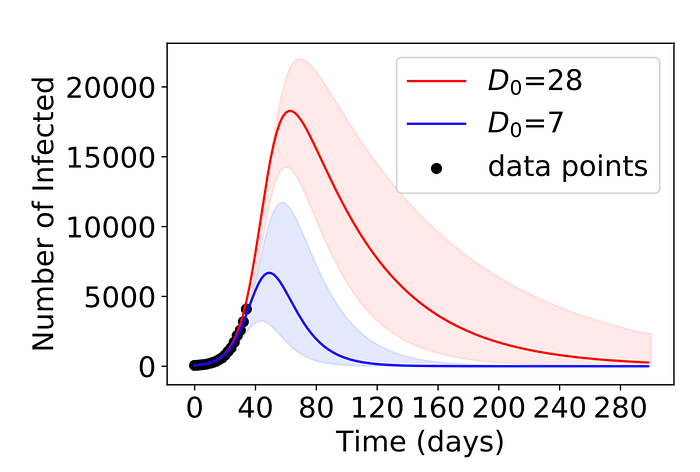
This is an example of what is known as an underspecification problem: many models explain the same data. As the 40 researchers wrote, underspecification presents significant challenges for the credibility of modern machine learning. It affects everything from tumour detection to self-driving cars, and (of course) language models.
From my own point of view, from 25 years experience working as an applied mathematician, what I find fascinating about the 40 researchers’ article is that applied mathematicians have been aware of the underspecification or identifiction problem for decades. Often there are a whole range of models that might explain a particular data set: how can we identify which one is best? The answer is that we can’t. Or at least we can’t do so without making and documenting further assumptions. If we want to model the spread of a disease, we make assumptions about peoples behaviour — how they will respond to a lockdown or to a vaccine’s arrival, etc. We know that not everything we assume can be measured. Assumptions thus document what we don’t know, but think might be the case.
In general, mathematical modelling consists of three components:
1, Assumptions: These are taken from our experience and intuition to be the basis of our thinking about a problem.
2, Model: This is the representation of our assumptions in a way that we can reason (i.e. as an equation or a simulation).
3, Data: This is what we measure and understand about the real world.
Where Google’s machine learning programme has been strong in the last five years is on the model (step 2). In particular, they have mastered one particular model: the neural network model of pictures and words. But this is just one model of many, possibly infinite many, alternatives. It is one way of looking at the world. In emphasising the model researchers persuing a pure machine learning approach make a very strong implicit assumption: that their model doesn’t need assumptions. As applied mathematicians have long known (and Google’s own group of 40 now argue) this simply isn’t the case. All models need assumptions.
The ‘model free’ assumption then leads to the stochastic parrot problem. One of the strengths that Deep Mind emphasise in their neural network approach is that it learns directly from the data. As a result, what their neural network models ultimately learn is nothing more (or less) than the contents of that data. For board games like chess and go or computer games like breakout, this isn’t a problem. The researchers can generate an infinite supply of data by simulating the games and win.
But for learning from words or from images, the data is a severely limited for two reasons. Firstly, human conversations are much more complex than games, involving our unspoken understanding of the meaning of objects (like the keys and the skulls in Montezuma Revenge). Secondly, we have access to only very limited data sets. Even billions of words on Reddit and gossip news sites — the favourite source for data — is only a very narrow representation of our language. You don’t have to be Wittgenstein to see that there is no way of learning our true language game in this way. The neural networks are nothing more than a compact representation of a gigantic database of words. So when GPT-3 or BERT ‘says’ something, all it is telling us is about some groups of sentences and grammar structures happen to occur together in the text. And since no assumptions are made by the model, then the only thing the neural networks learn, as Bender et al. point out, is to randomly parrot the contents of Reddit.
The important insight of, in particular, Timnit Gebru, Margaret Mitchell (another Google AI researcher) and Joy Buolamwini (at MIT) is that the technical challenges lie in finding ways to organise and construct language and image datasets in a way that is as ‘neutral’ as possible (one example from Gebru’s work on face recognition is shown in the figure below). And, even more importantly, we have to be honest that true neutrality in language and image data is impossible. If our text and image libraries are formed by and document sexism, systemic racism and violence, how can we expect to find neutrality in this data? The answer is that we can’t. If we use models that learn from Reddit with no assumed model, then our assumptions will come from Reddit. Bender, Gebru, Mitchell and Buolamwini show us that, if we are going to take this approach, then our focus should turn to finding ways of documenting data and models in a transparent and auditable way.

Is there hope for Google Brain? One glimmer can be found in the fact that most of the articles I cite here, criticising Google’s overall approach, are written by their own researchers. But the fact that they fired Gebru — the author of at least three of the most insightful articles ever produced by their research department and in modern AI as a whole — is deeply worrying. If the leaders who claim to be representing the majority of ‘Googlers’ can’t accept even the mildest of critiques from co-workers, then it does not bode well for the company’s innovation. The risk is that the ‘assumption free’ neural network proponents will double down on their own mistakes.
All great research must rise and then fall, as one model assumption takes over from another. As I wrote at the start of the article, the Deep Mind programme has generated impressive results. Many of the ideas which underlay this research were developed outside of Google — starting with decades of research by, for example, Geoffrey Hinton and colleagues — and were made primarily within the University system. It took those decades to realise the true potential in Hinton’s approach. Google gave the final push, providing time and computer resources to make the researchers’ dreams a reality.
What concerns me is that when Google’s own researchers start to produce novel ideas then the company perceives these as a threat. So much of a threat that they fire their most innovative researcher and shut down the groups that are doing truly novel work. I don’t want to downplay the deep instutionalised sexism and racism that is at play in Gebru’s firing — that is there for all to see. But I want to emphasise that Google has also done something deeply stupid. Instead of providing time and resources to their greatest minds, they are closing ranks and looking inwards at past achievements.
Its not often a clickbait question headline ends with an affirmative, but in this case it does: Google Brain’s research looks like it is on its way to implode.
Maybe one day we will see the transition from Hinton (ways of representing complex data in a neural network) to Gebru (accountable representation of those data sets) in the same way as we see the transition from Newton to Einstein. And when we do, it won’t be Google that should take the credit.
